TL;DR – When running appliances that require promiscuous mode it’s advised to place the appliance in the DFW exclusion list, especially if the appliance is a security hardened virtual appliance
Last year I was working with a customer that had rolled out NSX to implement micro-segmentation. This customer is a mid-sized customer that is integrating NSX into their existing production vSphere environment. The customer had decided to implement security policy based on higher level abstractions i.e. security groups but also decided they need security policy enforced everywhere, using the Applied To column set to Distributed Firewall. Not an ideal implementation but perhaps that discussion is for another blog post
The environment being a brownfield environment, the customer wanted to implement security policy to the existing virtual appliances. They were using F5 virtual appliance for load balancing and had specific requirements to configure promiscuous mode on the F5 port group to support VLAN groups(https://support.f5.com/kb/en-us/products/big-ip_ltm/releasenotes/product/relnotes_ltm_ve_10_2_1.html)
Long story short, by configuring the F5 port groups in promiscuous mode they were facing intermittent packet drops across the environment. We were quickly able to identify that the workloads impacted were the workloads that resided on the host that had the F5 virtual appliances. As we could not power off the appliance we decided to place the F5 appliance in an exclusion list and like magic, everything returned to normal, no packet drops.
Well now that we understood what was causing the issue but as with all things we needed to understand why this behaviour was seen. We started by picking a virtual machine on the F5 host and turned up logging on the rule that allowed traffic for a particular service, in this case, SSH. We also added a tag to that rule so we could filter the logs.
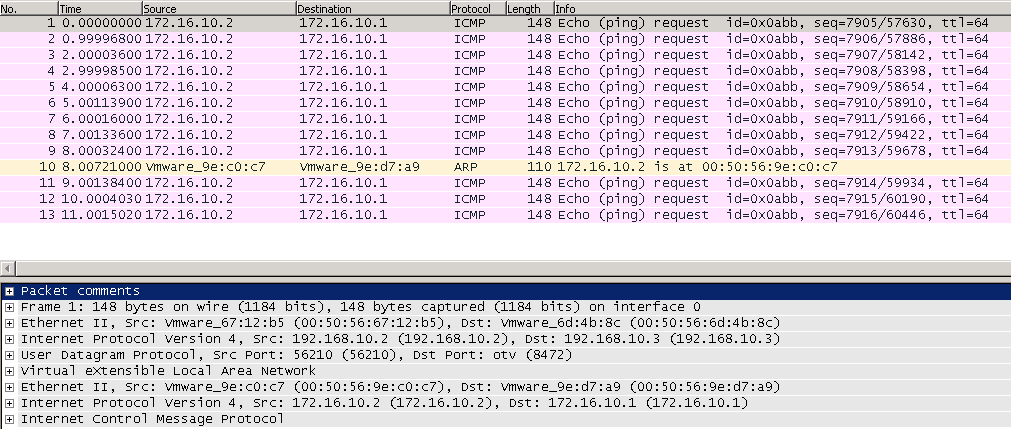
We started to follow an SSH session that we initiated from 10.68.0.250 to 10.68.145.170. We were seeing the SYN from 10.68.0.250 reaches 10.68.145.170 and this is allowed by the firewall as rule 1795 permits it but interestingly enough we were also seeing the same traffic flow on a different filter, in this case, 53210
Note: You can get the filter hash for a virtual machine by running vsipioctl getfilters. Each vNIC gets a filter hash
Looking at the output of vsipioctl getfilters we identified that the duplicate filter (53210) belonged to the F5 virtual appliance.
We also captured packets at the switchport of the virtual machine and we see 10.68.145.170 sending a SYN/ACK back to the client, this packet was also seen on both filters. The subsequent frame shows the client immediately sending a RST packet to close the connection. This was a bit strange as the firewall rule allows this traffic and there was no other reason why the client would immediately send a RST packet

Interestingly the dfwpktlogs had recorded packets on the duplicate filter hitting a different rule (rule 1026) and this rule had a REJECT action so a RST packet would be sent out for TCP connections
Why would traffic be hitting a different rule when the initial SYN was evaluated by rule 1795 ??
So, when a virtual machine is connected to a promiscuous portgroup its filter is also in promiscuous mode and hence its filter would receive all traffic. In this particular case, the F5 appliance was placed in security group that had its own security policy applied to it. Duplicated traffic that was sent to this filter was being subjected to this security policy. The security policy had a REJECT action configured and hence a RST packet was being sent to the client
Having identified this, we provided the customer with a couple of options to mitigate the issue.
I hope you found this article to be as interesting as this issue was to me.Until next time !!